|
NI introduced two new functions to the Application Control palette back in LabVIEW 2013, "Get Control Values by Index", and "Set Control Values by Index". These functions allow you to get or set control values faster than is possible with other VI Server objects, such as the Value property in the Control class. How much faster? How can I use this? How am I not learning about this until now? Read on... 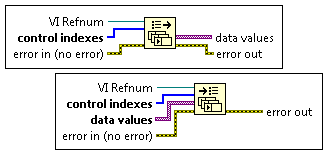 In the LabVIEW 2013 Features and Changes white paper NI states Use these functions to get or set control values faster than is possible with other VI Server objects, such as the Value property in the Control class. You can use these functions to get or set control values almost as fast as when you wire directly from or to a control terminal. However, these functions require more advanced application design than other methods for getting and setting control values. The first question I asked myself was just how does this feature stack up speed wise against the Value property, local variables, and wiring directly to the terminal? So I setup a simple benchmark for each use case so that I could compare them. 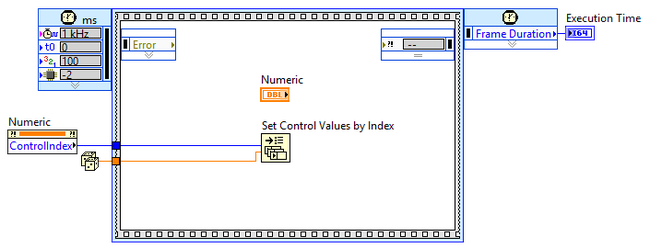 Based on my benchmarking it turned out that updating a control on a front panel with a local variable takes about 1.5 times longer than wiring directly to the terminal, a Value property node takes about 2750 times longer than wiring to the terminal, and the Set Control Values by Index node takes about 3.75 times longer than wiring to the terminal. Lets dig in to the reasoning behind these timing differences. When wiring directly to the terminal LabVIEW copies the data from its original memory location to the memory location for the control, meaning there is one copy operation. Because controls have a user interface attached, using controls to pass data has the side effect of redrawing controls, which adds memory expense and slows performance. Completing user interface actions uses more memory because LabVIEW switches from the execution thread to the user interface thread.  For example, when you set the Value property, LabVIEW simulates a user changing the value of the control, stopping the execution thread and switching to the user interface thread to change the value. Then LabVIEW updates the operation buffer that stores data at the control and redraws the control if the front panel is open. LabVIEW then sends the data back to the execution thread in a protected area of memory called the transfer buffer. LabVIEW then switches back to the execution thread. The next time the execution thread reads from the control, LabVIEW finds the data in the transfer buffer and receives the new value for the execution buffer that stores data on the block diagram.  When you write to a local or global variable, LabVIEW does not switch to the user interface thread. LabVIEW instead writes the value to the transfer buffer and then to the memory location for the control, meaning that there are two copy operations. The user interface updates at the next scheduled update time. It is possible to update a variable multiple times before a single thread switch or user interface update occurs. This is possible because variables operate solely in the execution thread. 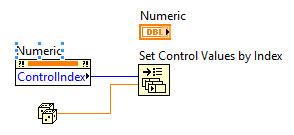 The reason that the Control Value by Index functions take in a VI Refnum as an input is because under the hood, when this function is executed, LabVIEW is indexing an array of references to the Front Panel controls of the referenced VI, getting the reference for the indexed control, and copying data into the memory location for the control. This process only requires one copy operation (like writing directly to the terminal), but has the extra overhead of indexing the array of control references. 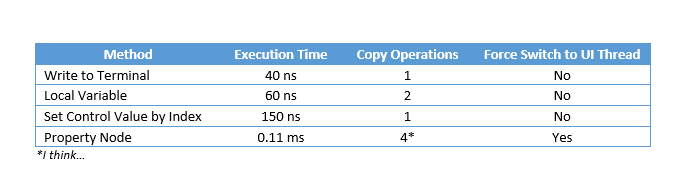 So it's fast, but why would I use it? Well it's not as fast or efficient as wiring directly to a terminal, but you can't always write to a terminal. A use case for this would be decoupling the front panel from the block diagram. When you want to abstract your UI away from your business logic you end up having at least two separate VI's. One VI handles the logic needed to drive UI functionality, and the other VI handles the functional part of the software that does something. Ideally these two VI's should be decoupled to the point where the UI doesn't care what its data source is, and the data source doesn't care what its UI is. When I learned about this feature, the first thing I thought of was something I saw presented by Dmitry Sagatelyan at the 2015 CLA Summit. Dmitry had put together a very slick implementation of the event aggregator pattern that he used to decouple data producers from data consumers. I won't go into much detail on it here (saving that for a future blog post) but after seeing his presentation I immediately started tinkering with writing my own. One of the ideas that the event aggregator abstracts away is the transport mechanism used to send/receive messages containing data between the producer(s)/consumer(s) of data (I dont mean Producer/Consumer in the LabVIEW architecture sense here). Traditionally the message transport mechanism is queues, notifiers, events, TCP etc., and these fit the paradigm fantastically. But why not create a message transport mechanism based around the Set Control Values by Index function? I don't go into implementation detail here, mainly because it necessitates an understanding of the event aggregation pattern. The demo above is using a message transport built around the Set Control Values by Index function on the consumer side, and a queue message transport on the producer side. 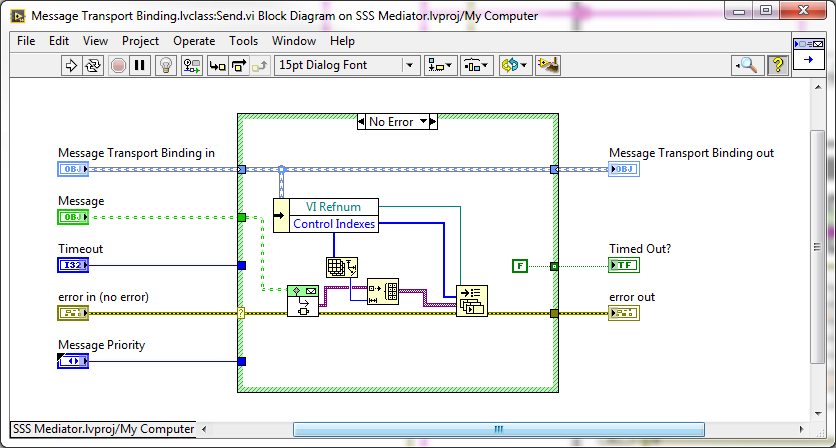 The benefit of the Set Control Values by Index message transport is that I can bind a Control in one place in my application to data being generated somewhere else in my application. Of course, I could always have done this using a reference to the control and a Value property node but I never did because it was prohibitively expensive. The Set Control Values by Index function provides me with a much more efficient mechanism, where the efficiency trade off is worth the simplicity it provides for the right use case. Have you used this feature before? If so, how did you use it and how did you like it? Let me know in the comments section below. Updated on 11/4/2015 to include better benchmark data and better explanation of Control Value by Index under the hood. Big thanks to Earl from NI! Jon McBee is a Principal Software Engineer at Cambridge NanoTech and is a Certified LabVIEW Architect, Certified LabVIEW Embedded Developer, Certified TestStand Developer, an NI Certified Professional Instructor, and a LabVIEW Champion
8 Comments
Jim Fowler
11/17/2015 11:38:53 am
Excellent summary, Jon. I remember running across much of this information at various times, but never in one place.
Jon McBee
11/23/2015 04:36:17 pm
This video and the pub/sub video were made before I owned a mic, in fact these videos lack of audio is what prompted me to purchase a mic. I have been planning on re-recording those two so that they include audio, I will see if I can do that this evening. 12/2/2015 08:36:15 pm
Hello Jon,
Jon McBee
12/3/2015 07:15:09 am
Hey Russell,
Thomas
9/8/2018 02:56:15 pm
What about the Front Panel Invoke Node "Ctrl Val.Set"? That's another way of doing decoupled read/write. I doubt it's faster than ctrl index's. Should we test it for comparison purposes? Leave a Reply. |
Tags
All
Archives
October 2019
LabVIEW Blogs |
 RSS Feed
RSS Feed

Powered by the Panda Ant
|